


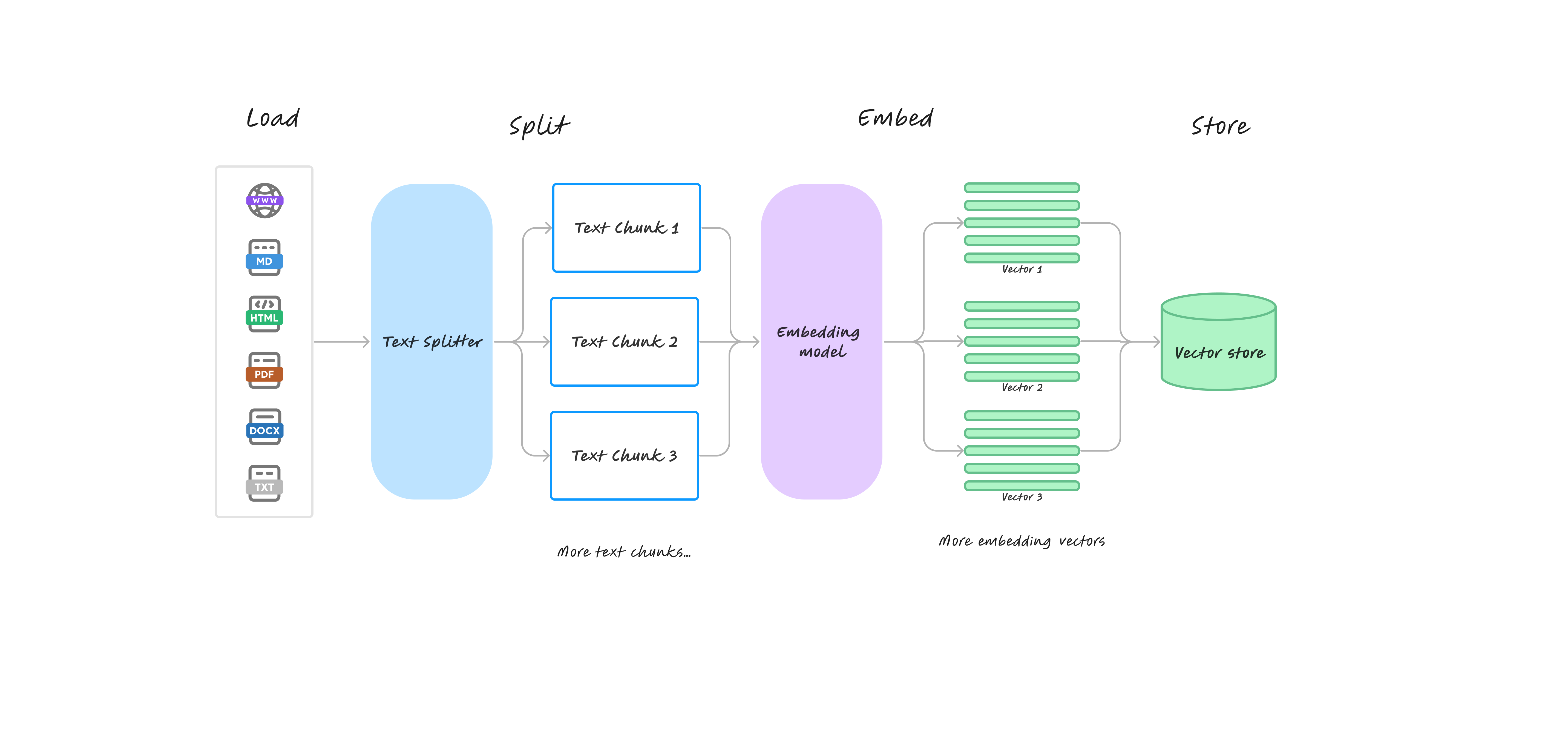
Retrieval-Augmented-Generation (RAG) is a cutting-edge method to enhance the capabilities of large language models by integrating external data retrieval directly into the generative process. This approach combines the robust generative abilities of a pre-trained language model with real-time access to an expansive external knowledge base. During operation, RAG first retrieves relevant documents or data from a vector database in response to a query. This retrieved information then informs and guides the generation of the model's responses, thereby enriching the context and accuracy of its output.
RAG vs. Fine-Tuning
RAG and fine-tuning are both techniques aimed at enhancing language models by leveraging additional information. However, they differ fundamentally in how this information is incorporated and utilized.
Dynamic vs. Static Learning:
RAG operates by dynamically querying an external database during the inference phase, allowing it to access and incorporate the most relevant and current information for each query. This stands in contrast to fine-tuning, where external data is statically integrated into the model’s learning process, becoming part of the model's parameters. Once a model is fine-tuned, updating it to reflect new information necessitates additional rounds of training.
Flexibility and Scalability:
The flexibility of RAG comes from its ability to integrate updates in the external database without needing to retrain the model. This makes it particularly valuable in scenarios where information is updated frequently or where real-time data is crucial. On the other hand, fine-tuning requires the model to be retrained with new data to reflect changes, which can be both time-consuming and resource-intensive.
Computational Efficiency and Cost:
In terms of computational demands, RAG's reliance on external databases for retrieval can be computationally expensive. However, this is often offset by the reduced need for frequent retraining. Vector databases help in optimizing the retrieval process, thus potentially lowering operational costs. In contrast, fine-tuning involves significant computational resources and expertise, particularly when dealing with large datasets or continuous updates, leading to higher costs.
Application-Specific Adaptation:
RAG allows for tailored responses by customizing the external database, thus providing targeted and contextually appropriate outputs based on the specific data retrieved. Fine-tuning, while effective, generalizes from the data it was trained on and might not align perfectly with specific real-world scenarios unless the model is continuously updated to adapt to new contexts.
RAG with TaskingAI
TaskingAI has effectively implemented a hybrid RAG that combines long-window AI models with vector-based semantic search. The feature is designed to enhance information processing by leveraging the strengths of both long context windows and sophisticated search capabilities.
The primary advantage of this approach is its ability to enrich the AI's functionality without modifying its core architecture. By integrating extended memory for longer context windows with advanced search features that access real-time data and expert databases, TaskingAI taps into a broad spectrum of internal and external knowledge sources.
This combination allows the model to achieve a more nuanced understanding of user intent and to efficiently locate relevant data across extensive databases. The enriched context window provided by the smart search ensures that the information is not only relevant but also precisely aligned with user queries. This capability significantly improves the overall effectiveness of the long context windows, enhancing the integration and refinement of search results.
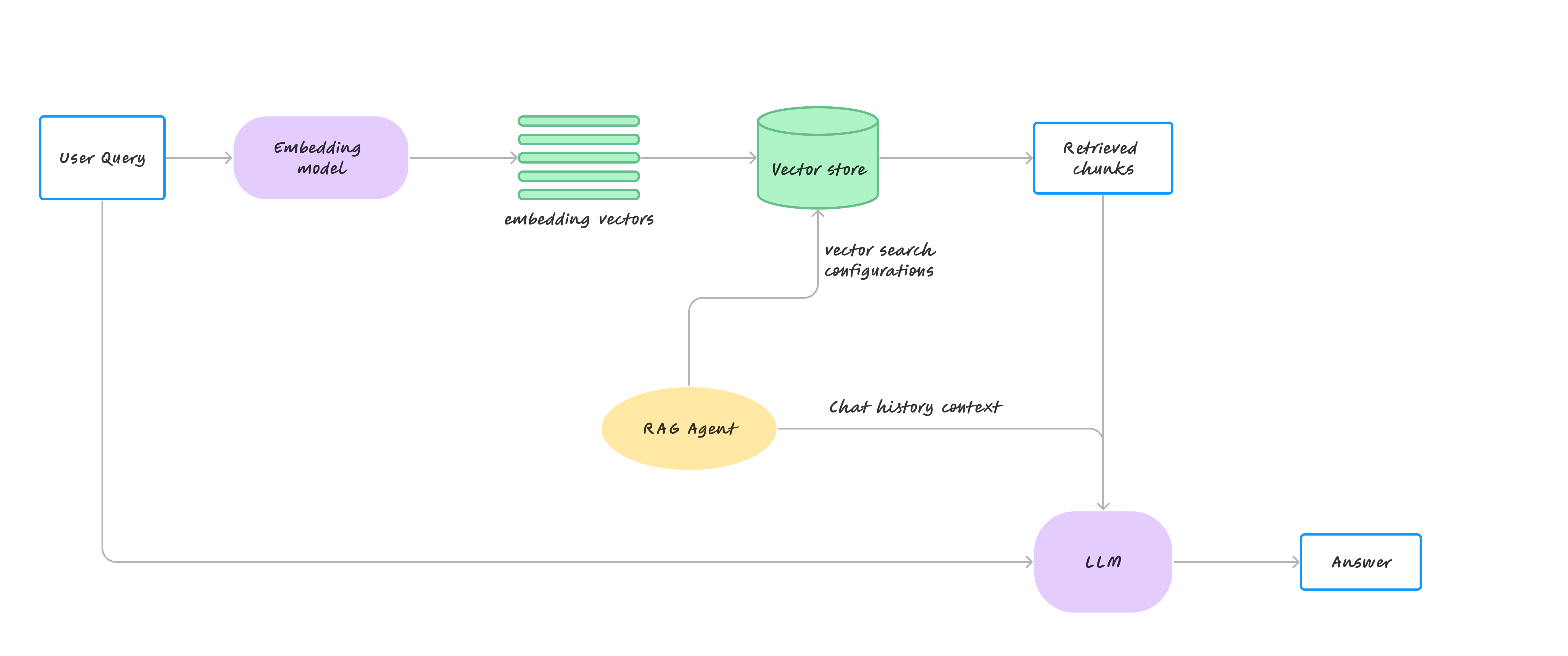
TaskingAI's hybrid feature stands out for its user-friendly interface and stable performance, distinguishing it from other alternatives in the market. By creating a robust, closed-loop network of capabilities, TaskingAI ensures that its outputs are accurate, contextually enriched, and tailored to meet specific user needs. This approach underscores TaskingAI's commitment to providing advanced, practical AI solutions that are both accessible and reliable in complex information environments.
By extending the context window's capacity and coupling it with TaskingAI's advanced retrieval modules, the system can access a broader range of text, potentially improving information access by several hundred times. This sets new benchmarks for model performance and efficiency.
Code Example
In the following example, we'll illustrate how to use TaskingAI to manage a RAG (Retrieval-Augmented Generation) agent.
Prepare Retrieval Data Source
First, an appropriate embedding model needs to be selected for performing vector computations. Next, storage space needs to be allocated for the unstructured data records, which is a process known as creating a collection in TaskingAI.
1import taskingai
2
3# choose an available text_embedding model from your project
4embedding_model_id = "YOUR_MODEL_ID"
5
6collection = taskingai.retrieval.create_collection(
7 embedding_model_id=embedding_model_id,
8 capacity=1000, # maximum text chunks can be stored
9)
10
11# Check collection status.
12# Only when status is "READY" can you insert records and query chunks.
13print(f"collection status: {collection.status}")Printed result: collection status: ready
Next, we'll create three unique records with differing topics: "Machine Learning", "Michael Jordan", and "Granite".
1# create record 1 (machine learning)
2taskingai.retrieval.create_record(
3 type="text",
4 collection_id=collection.collection_id,
5 content="Machine learning is a subfield of artificial intelligence (AI) that ...",
6 text_splitter={"type": "token", "chunk_size": 100, "chunk_overlap": 10},
7)
8
9# create record 2 (Michael Jordan)
10taskingai.retrieval.create_record(
11 type="text",
12 collection_id=collection.collection_id,
13 content="Michael Jordan, often referred to by his initials MJ, is considered ...",
14 text_splitter={"type": "token", "chunk_size": 100, "chunk_overlap": 10},
15)
16
17# create record 3 (Granite)
18taskingai.retrieval.create_record(
19 type="text",
20 collection_id=collection.collection_id,
21 content="Granite is a type of coarse-grained igneous rock composed primarily ...",
22 text_splitter={"type": "token", "chunk_size": 100, "chunk_overlap": 10},
23)This process can be adapted to add additional records as needed in the future. TaskingAI offers a flexible framework to manage retrieval tasks efficiently.
Semantic Search
To evaluate the efficiency of the vector index on the given collection, we can carry out a semantic search using the query_chunks API.
1# query chunks 1
2chunks = taskingai.retrieval.query_chunks(
3 collection_id=collection.collection_id,
4 query_text="Basketball",
5 top_k=2
6)
7print(chunks)When we run this code, the result will be:
1[Chunk(chunk_id='LmK0UMmABaOrUOw6w3w2DVxa', record_id='qpEasW5yfWFVhvaBg1SyE2nZ', collection_id='DbgYii02350j8tm5igX50oeo', content='2021, he is the majority owner of the Charlotte Hornets. Off the court, Jordan...', num_tokens=87, metadata={}, score=0.40253750070706085, updated_timestamp=1713513137746, created_timestamp=1713513137746), Chunk(chunk_id='LmK0IBth1CDlxE26QSMVQAwB', record_id='qpEasW5yfWFVhvaBg1SyE2nZ', collection_id='DbgYii02350j8tm5igX50oeo', content='Michael Jordan, often referred to by his initials MJ, is considered...', num_tokens=92, metadata={}, score=0.33793092739993824, updated_timestamp=1713513137741, created_timestamp=1713513137741)]As you can observe, the query_chunks command effectively returned relevant content - precisely the information that we initially stored. Moreover, you are also encouraged to conduct additional tests using other sample queries for further exploration.
Assistant with RAG
The example demonstrates how to create a specialized assistant, which is designed to have expertise in specific areas mentioned before.
First you'll need to specify a chat completion model ID for the underlying AI model. The assistant is then configured with a name, description, a simple memory model, and a collection of documents it can retrieve information from.
1import taskingai
2
3# choose an available chat_completion model from your project
4model_id = "YOUR_MODEL_ID"
5
6assistant = taskingai.assistant.create_assistant(
7 model_id=model_id,
8 name="My Assistant",
9 description="A assistant who knows Machine Learning, Michael Jordan and Granite.",
10 memory={"type": "naive"},
11 retrievals=[{"type": "collection", "id": collection.collection_id}],
12)
13print(f"created assistant: {assistant}\n")Response outputs:
1created assistant: assistant_id='X5lMtDt3TBkZ6Kw8VNP1PDBN' model_id='Tpnig895' name='My Assistant' description='A assistant who knows Machine Learning, Michael Jordan and Granite.' system_prompt_template=[] memory=AssistantMemory(type=<AssistantMemoryType.NAIVE: 'naive'>, max_messages=None, max_tokens=None) tools=[] retrievals=[RetrievalRef(type=<RetrievalType.COLLECTION: 'collection'>, id='DbgYat44oLayaL3y7awkLU03')] retrieval_configs=RetrievalConfig(top_k=3, max_tokens=None, method=<RetrievalMethod.USER_MESSAGE: 'user_message'>) metadata={} updated_timestamp=1715416402312 created_timestamp=17154164023121# create a new chat session
2chat = taskingai.assistant.create_chat(
3 assistant_id=assistant.assistant_id,
4)
5
6# send user query
7taskingai.assistant.create_message(
8 assistant_id=assistant.assistant_id,
9 chat_id=chat.chat_id,
10 text="What is Machine Learning?",
11)
12
13# generate assistant's response
14response = taskingai.assistant.generate_message(
15 assistant_id=assistant.assistant_id,
16 chat_id=chat.chat_id,
17)
18
19print(response)Response outputs:
1message_id='Mah1d7IA2DNUCeCXWN9ULcbe' chat_id='SdELBOS2qffXx04U7Rw264we' assistant_id='X5lMtDt3TBkZ6Kw8VNP1PDBN' role='assistant' content=MessageContent(text='Machine learning is a branch of artificial intelligence that involves developing algorithms that enable computers to learn from and make predictions or decisions based on data. These algorithms are designed to improve automatically through experience, without being explicitly programmed to do so. Machine learning can be applied to various tasks, such as image categorization, data analysis, and prediction models, among others.') metadata={} logs=[] updated_timestamp=1715416405249 created_timestamp=1715416405249Feel free to adjust the model and retrieval integrations as per your configuration, and explore more scenarios where such an assistant could be beneficial.



